Stop Saving to Disk with C# Asynchronous Streams
My journey to solve a hard performance problem with a new-ish language feature: asynchronous streams. This post explains what asynchrnous streams are, and shows a real-world problem they can solve.

Recently I faced a fun performance challenge and ended up reducing a 3 hour job to 1.5 hours, thanks to an awesome recent C# language enhancement: Asynchronous Streams. Whoa, so 2019 I hear you say. I'm sure you've read some headlines and skimmed some blog posts, but have you really grokked this technology and what it means? I hadn't. In this post I'll quickly explain what asynchronous streams are, describe what real world problem they helped me solve, and show some common pitfalls just in case you're in a similar situation.
What Are They?
In short, asynchronous streams are a language feature introduced in C# 8 that allow you to process a stream of data ... asynchronously. Right, obviously. An example will help.
IAsyncEnumerable<int> numbers = Producer.GetNumbersAsync();
await foreach (var number in numbers)
{
if (number > 10) break;
}
Above we're retrieving a set of numbers of type IAsyncEnumerable (an interface introduced in C# 8) and iterating over the first 10 of them with await foreach (a new language feature also introduced in C# 8).
What's fancy here is that each iteration of the loop has a hidden await that creates a continuation and returns control to the caller, until such a time as the data provider has a new number to provide. That returning of control to the caller is generally what await, introduced in C# 5, does. It frees the host up to refresh the UI of mobile apps or perhaps respond to HTTP requests. What's new with IAsyncEnumerable is that await is now a first class citizen when it comes to enumerables.
You can see how it works if you open up the code from the prior example in ILSpy. If you decompile and view it as a release prior to C# 8 (ILSpy is awesome that way).
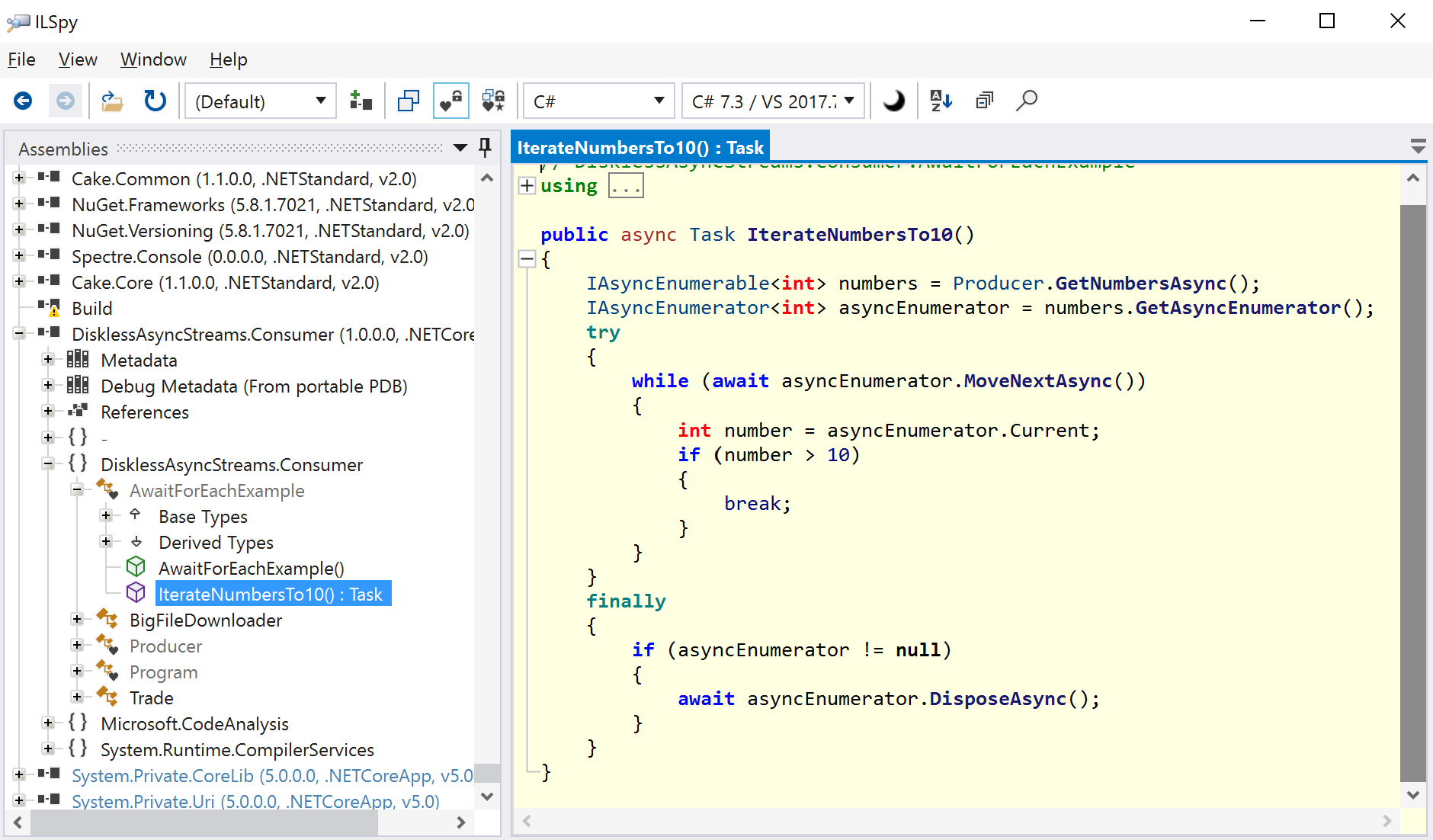
Then you end up with this:
IAsyncEnumerable<int> numbers = Producer.GetNumbersAsync();
IAsyncEnumerator<int> asyncEnumerator = numbers.GetAsyncEnumerator();
try
{
while (await asyncEnumerator.MoveNextAsync())
{
int number = asyncEnumerator.Current;
if (number > 10)
{
break;
}
}
}
finally
{
if (asyncEnumerator != null)
{
await asyncEnumerator.DisposeAsync();
}
}Now you can clearly see that IAsyncEnumerable works almost exactly like IEnumerable did with its .MoveNext and .Current methods. Except three things:
1. The method names are suffixed with the word Async
2. Everything is task-based
3. There's some extra cleanup going on
Interesting, but how useful remains to be seen.
Obscure Language Feature: Meet Real World
On my project we need to download and process large files daily. Think 60 Gig CSV files. Technically they're 60 Gig BSON files. If they were CSV they'd be even larger. Whatever, the point is that we need to read and process a lot of data, and it's slow. It takes hours. And that's a problem because the data needs to be ready by a certain time of day and if something goes wrong we have to start over. So we only get a couple shots, and worse: the data is going to get even bigger in the future for this customer. We needed to find performance optimizations now.
Historically we'd treated this process in several steps like:
- Download file
- Read and process file (using DataFlow from the Task Parallel Library, which if you aren't familiar, you should go drop everything and learn about)
- Insert results (only about 90 megs) into database
That's simplified but overall those three steps took over 2 hours. Downloading: ~40 minutes. Reading and processing: ~1.5 hours. Inserting: ~10 minutes.
The team spent a lot of time brainstorming solutions to performance. But there was one thing that was bugging me about that process. Maybe reread the the bullet points and see if anything stands out.
Answer: Why were we saving to disk and reading from disk at all?! Theoretically this is why streams exist. We should be able to download the data and process it down into 90 megs and never hit the disk at all. Right?!
Also, that IO sounds slow, but that's a different story.
Capture Content As Stream?
But I didn't know if asynchronous streams could be applied to downloading large files over HTTP. First of all, the team had been downloading zip files in BSON. I needed the data to be consumable as a stream, so zipping was right out. Consuming BSON as a stream eventually turned out to be doable, but that came later and is beyond the scope of this post. Thus unzipped CSV for the first pass.
Fortunately, there was a way to specify in the data provider's API that we wanted unzipped CSV content. That was going to increase the download time, but I was betting we'd make it up during processing, since the disk appeared to be such a bottleneck.
Next I was curious if the TCP packets started immediately upon request and broke at newline boundaries. Important? Not sure, although it does make a good picture for a blog post.
Wireshark packets looked like this:
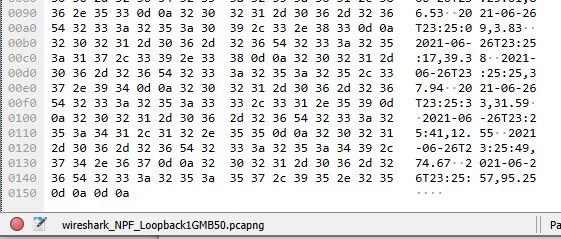
In other words this was a packet:
`U0(ñòßGAäwÆMP'Û10d
2021-06-26T23:24:45,10.79
2021-06-26T23:24:53,97.83
2021-06-26T23:25:01,86.53
2021-06-26T23:25:09,3.83
2021-06-26T23:25:17,39.38
2021-06-26T23:25:25,37.94
2021-06-26T23:25:33,31.59
2021-06-26T23:25:41,12.55
2021-06-26T23:25:49,74.67
2021-06-26T23:25:57,95.25Some random meta-data at top, but it ends with a newline. Great.
Incidentally, that's actually the result of an app I built to simulate our actual data provider for the purposes of this blog post. It's called DisklessAsynchronousStreams (maybe don't try to say that 10 times fast). It's open source if you feel like exploring the code of this post in more detail.
Asynchronous Consumption
p.s. ⬆️ That's a fantastic subheading, and will absolutely be the next big diet fad, just wait and see.
Getting back to the point, I soon learned the important magic for asynchronously pulling data without writing to disk is the setting the HttpCompletionOption.ResponseHeadersRead flag when calling GetAsync() or SendAsync() on the HttpClient. That tells the compiler to block only until the headers are received, then continue execution. Then calls to ReadLineAsync() may proceed while data is still downloading. More specifically:
using var response = await httpClient.GetAsync(
uri, HttpCompletionOption.ResponseHeadersRead);
response.EnsureSuccessStatusCode();
await using var stream = await response.Content.ReadAsStreamAsync();
using var streamReader = new StreamReader(stream, Encoding.UTF8);
while (!streamReader.EndOfStream)
{
var line = await streamReader.ReadLineAsync();
var trade = GetTradeFromLine(rowNum, line);
yield return trade;
}The above code works, but only because of C# 8. Prior to C# 8 the return type would need to be async Task<IEnumerable<Trade>> . Seems reasonable. Except, the compiler then gives you:
The return type of an async method must be void, Task, Task<T>, a task-like type, IAsyncEnumerable<T>, or IAsyncEnumerator<T>
The easy solution with C# 8 and IAsyncEnumerable though is to return IAsyncEnumerable that can then subsequently be consumed with async foreach.
private async IAsyncEnumerable<Trade> StreamReadLines()
{
...
}p.s. if you're shaky on how yield works check out How System.Linq.Where() Really Works
Asynchronous Limitations
Here's an interesting error, guess what it means:
Type: System.IO.IOException
Message: Unable to read data from the transport connection: An existing connection was forcibly closed by the remote host.
Inner exception:
Type: System.Net.Sockets.SocketError
SocketErrorCode: ConnectionReset
Message: An existing connection was forcibly closed by the remote host.
StackTrace:
...
at System.IO.StreamReader.d__67.MoveNext()
System.IO.StreamReader.d__59.MoveNext
If you said the remote host closed the connection on us, congratulations you can read, but sadly that is not at all what happened. The actual problem is the consumer exceeded a buffer (it happens to the best of us) and then .NET lied to us and that made us sad.
The problem occurs when the consumer is too slow in reading the data from the producer. Basically if data is coming in faster than we're processing it then someone needs to hold that data in a certain sized slot of memory, and eventually data will exceed the size of the slot.
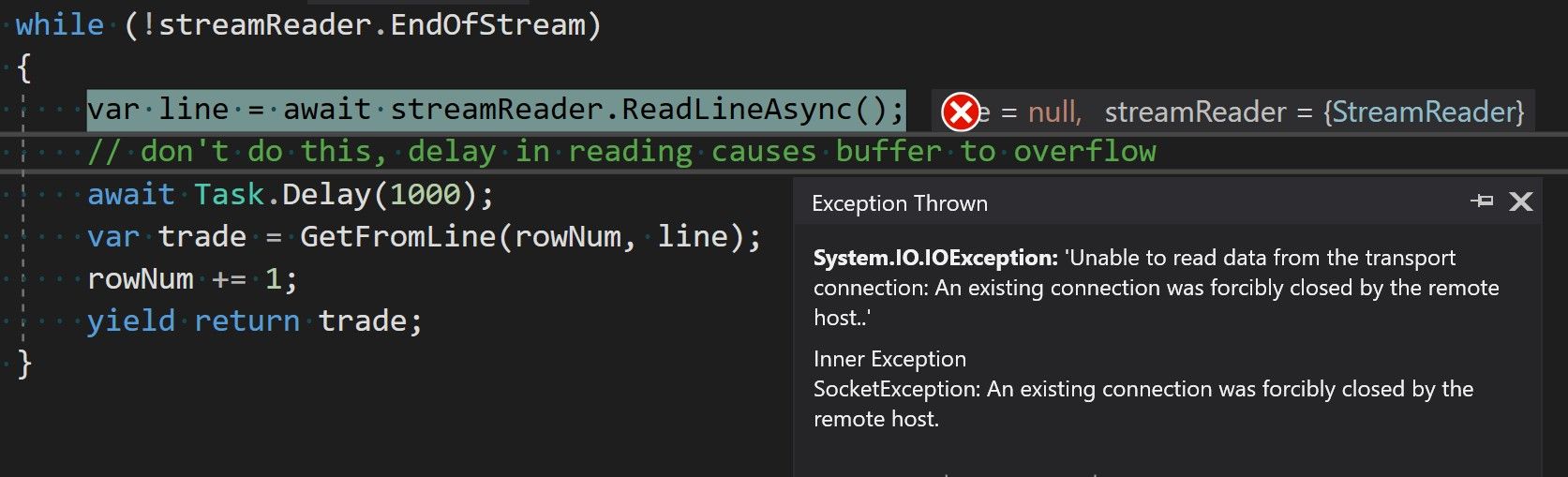
Interestingly you can make it happen faster by setting a smaller value of MaxResponseContentBufferSize on HttpClient. Unfortunately, you cannot set MaxResponseContentBufferSize beyond its default size of 2 Gigs. Therefore make sure you don't do anything slow inside your main message processing loop.
One More Gotcha
Don't expect consumers to successfully stream read data asynchronously with Fiddler open. Fiddler is awesome for watching regular HTTP traffic, but it batches entire requests up before forwarding them, and next thing you know you've wasted 30 minutes trying to figure out why you can't reproduce your production environment on a duplicate project while writing up a blog post. Heed my warning: don't be that person.
Conclusion
Great, so I stopped saving data to disk but increased my download size substantially. But was it worth it? Fortunately, I was very happy to discover a 50% reduction in batch processing time. Also, it consumed less memory and CPU and electricity and cooling costs, and then the planet sent me a personal thank you note that I've got up on my fridge. Your results may vary.
Speaking of: this code is harder to maintain, so use it sparingly. But diskless asynchronous streams is a great technique to know about if you find the right problem. With any luck you too start a new diet fad or be personally appreciated by a celestial body.