How to Increase Quality with a Code Coverage Hack
In this post I'll summarize what code coverage is, how it can be abused, but also how it can be leveraged to gently increase design and architecture quality, reduce bug regressions, and provide verifiable documentation.


But first a short story:
The Hawthorne Effect
From 1924 to 1932, a Western Electric company called Hawthorne Works conducted productivity experiments on their workers. The story goes like this:
First, they increased lighting and observed that productivity went up. Enthused, they increased lighting further and productivity went even higher
Before reporting the fantastic news that increasing productivity would be cheap and easy, they tried decreasing lighting as a control. To their horror instead of productivity decreasing as predicted it now soared!
What was going on?!
The conclusion they eventually reached was that lighting was completely unrelated to productivity and that the workers were more productive the more they felt they were being observed. This psychological hack has been dubbed The Hawthorne Effect or the observer effect.
Leverage A Psychological Hack
If you're wondering what this has to do with software development, the Hawthorne Effect is a tool that can be leveraged by astute managers and team leads to gently increase quality on a team. Instead of forcing unit testing on possibly reluctant team members, leads can regularly report on the one metric, and as with the Hawthorne Effect, teams will feel the effects of being observed and naturally want to increase their number.
If it sounds too good to be true keep in mind this is obviously more relevant for newer or less mature teams than highly functioning ones. Or, perhaps you doubt that quality will increase in conjunction with code coverage. Before we can get there we should cover (see what I did there) what it is.
What is Coverage?
According to Wikipedia
Coverage is a measure used to describe the degree to which the source code of a program is executed when a particular test suite runs.
Or put another way it's a percentage that shows how many lines of production code have been touched by unit tests. An example will help.
Consider this method:
public static string SayHello(string name)
{
if (string.IsNullOrEmpty(name))
{
return "Hello Friend";
}
else
{
return "Hello " + name;
}
}If you have just a single (XUnit) unit test like this:
[Fact]
public void Test1()
{
var actual = Class1.SayHello("Bob");
Assert.Equal("Hello Bob", actual);
}Then it will cover ever line of code except for the "Hello Friend" line.
On C# based projects there's this amazing tool called NCrunch that runs tests continuously. It calculates the SayHello method as five lines of code. It shows covered lines with green dots and uncovered lines as white:
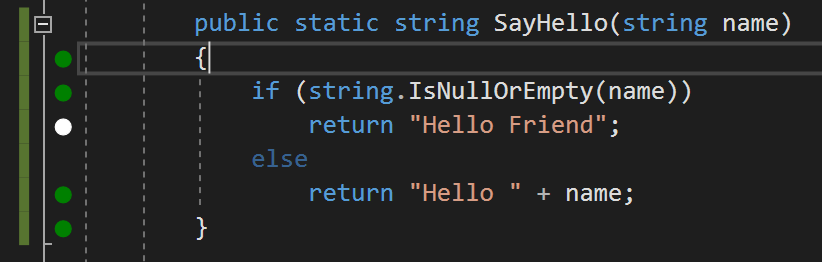
Since four of those lines are touched by tests the result is a code coverage of 4/5 or 80%.
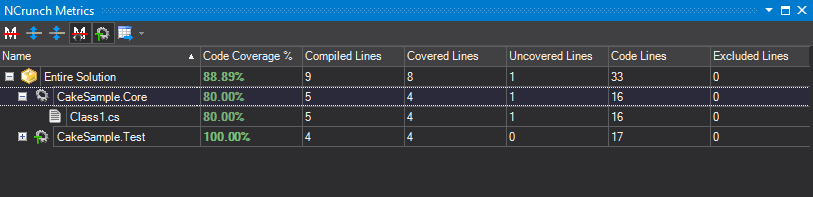
As a quick aside I find continuous testing tools like NCrunch and its JavaScript cousin Wallaby.js to be extremely motivating -- fun even. Doesn't that white dot just bug the OCD in you? They're also a huge productivity enhancer thanks to their nearly instantaneous feedback. And another bonus: they also report coverage statistics. If you're looking to increase quality on a team consider continuous testing tools, they pay for themselves quickly.
How to Cheat
If you're concerned that sneaky developers will find some way to cheat the number, make themselves look good, and not increase quality at all, you're not entirely wrong. As with any metric, coverage can be cheated, abused, and broken. For one thing, I've known at least one developer (not me I swear) who wrote a unit test to use reflection to loop through every class and every property to ensure that setting the property and subsequently getting it resulted in the property that was set.
Was it a valuable test? Debatable. Did it increase code coverage significantly to make one team look better than the others to a naive observer? Absolutely.
On the opposite side of the spectrum consider this code:
public bool IsValid()
{
return Regex.IsMatch(Email,
@"^(?("")("".+?(?<!\\)""@)|(([0-9a-z]((\.(?!\.))|" +
@"[-!#\$%&'\*\+/=\?\^`\{\}\|~\w])*)" +
@"(?<=[0-9a-z])@))(?(\[)(\[(\d{1,3}\.){3}\d{1,3}\])|" +
@"(([0-9a-z][-0-9a-z]*[0-9a-z]*\.)" +
@"+[a-z0-9][\-a-z0-9]{0,22}[a-z0-9]))$");
}A developer could get 100% code coverage for that method with a single short test. Unfortunately, that one line method has an insane amount of complexity and should actually contain perhaps hundreds of tests, not one of which will increase the code coverage metric beyond the first.
The thing about cheating code coverage is that even if developers are doing it, they're still writing tests. And as long as they they keep a continued focus on writing tests they'll necessarily begin to focus on writing code that's testable. And as Michael Feathers, author of Legacy Code, points out in one of my favorite presentations The Deep Synergy between Testability and Good Design,
Testable code is necessarily well designed
Go watch the video if you don't believe me (or even if you do and haven't watched it yet).
The trick, however, is to keep the focus on code coverage over time, not just as a one time event.
The Ideal Number
In order to maintain a focus on code coverage over time, perhaps setting a target goal would be a good approach. I'm usually a little surprised when I ask "What's the ideal coverage number?" at local user groups and routinely hear answers like 80%, 90%, or even 100%. In my view the correct answer is "better than last sprint" -- or at least no worse. Or in the immortal words of Scott Adams (creator of Dilbert): goals are for losers, systems are for winners.
To that end, I love that tools like VSTS don't just report code coverage, they show a chart of it over time. But while incorporating coverage in the continuous integration process is a great starting point, as it provides a single source of truth, great teams incorporate the number into other places.
I've written about the importance of a retrospective before, but I feel it's also the perfect venue to leverage the Hawthore Effect to bring up the topic of coverage on a recurring basis. The retrospective can also be an excellent opportunity for positivity. For instance, a code coverage of 0.02% may not sound great, but if coverage was 0.01% the prior sprint that could legitimately show up on a retrospective under "what we did well" as doubled the code coverage!.
Summary
Even if a team abuses the code coverage metric to some degree, a sustained interest in testing through ongoing reporting can gradually and incrementally allow a team to reap the benefits of unit testing. As a team writes more tests their code will become more testable, their testable code will become more loosely coupled and better architected, their bugs will regress less often, they'll end up with verifiable documentation, and small refactorings will become more common because they are safer and easier. In short the team will increase in maturity and their product will increase in quality.
As always if you agree or disagree I'd love to hear about it in the comments or on twitter.